The history of software development is that of a practice born in the aftermath of the second world war, one which trickled down to broader and broader audiences at the eve of the twenty-first century. Through this development, various paradigms, platforms and applications have been involved in producing software, resulting in different epistemic communities (
author, year)
and communities of practice (
Hayes, 2015)
, in turn producing different types of source code. Each of these write source code with particular characteristics, and with different priorities in how knowledge is produced, stored, exchanged, transmitted and retrieved. In this section, we take a socio-historical stance on the field of programming, highlighting how diverse practices emerge at different moments in time, how they are connected to contemporary technical and economic organizations, and for specific purposes. Even though such types of reading and writing source code often overlap with one another, this section will highlight a diversity of ways in which code is written, notably in terms of origin—how did such a practice emerge?—, references—what do they consider good?—, purposes—what do they write for?—and examples—how does their code look like?.
First, we take a look at the software industry, to identify professional software developers , the large program texts they work on and the specific organizational practices within which they write it. They are responsible for the majority of source code written today, and do so in a professional and productive context, where maintainability, testability and reliability are the main concerns. Then, we turn to a parallel practice, one that is often exhibited by software developers, as they also take on the stance of hackers . Disambiguating the term reveals a set of practices where curiosity, cleverness, and idiosyncracy are central, finding unexpected solutions to complex problems, sometimes within artificial and playful constraints. Scientists operate within an academic environment, focusing on concepts such as simplicity, minimalism and elegance; they are often focused on theoretical issues, such as mathematical models, as well as programming language design, but are also involved in the implementation of algorithms. Finally, poets read and write code first and foremost for its textual and semantic qualities, publishing code poems online and in print, and engaging deeply with the range of metaphors allowed by this dynamic linguistic medium.
While this overview encompasses most of the programming practices, we leave aside some approaches to code, mainly because they do not directly engage with the representation of source code as a textual matter. More and more, end-user applications provide the possibility to program in rudimentary ways, something referred to as the "low-code" approach (
author, year)
, and thus contributing to the blurring of boundaries between programmers and non-programmers5.
Software developers
As Niklaus Wirth puts it, the history of software is the history of growth in complexity (
author, year)
, while also following a constant lowering of the barrier to entry to the tools through which this complexity is managed. As computers' technical abilities in memory storage and processing power increased year on year since the 1950s, the nature of writing computer instructions shifted as well.
From machine dependence to autonomous language
In his history of the software industry, Martin Campbell-Kelly traces the development of a discipline through an economic and a technological lens, and he identifies three consecutive waves in the production of software (
Campbell-Kelly, 2003)
From airline reservations to Sonic the Hedgehog : A history of the software industry by Martin Campbell-Kelly, 2003. [link]
. Starting in the 1950s, and continuing throughout the 1960s, software developers were contractors hired to work directly with a specific hardware. These mainframes were large, expensive, and rigid machines, requiring platform-specific knowledge of the corresponding Assembly instruction set, the only programming language available at the time6. Two distinct groups of people were involved in the operationalization of such machine: electrical engineers, tasked with designing hardware, and programmers, tasked with implementing the software. While the former historically received the most attention (
author, year)
, the latter was mostly composed of women and, as such, not considered essential in the process (
author, year)
. At this point, then, programming remains hardware-dependent7.
In the 1960s, hardware switched from vacuum tubes to transistors and from magnetic core memory to semiconductor memory, making them faster and more capable to handle complex operations. On the software side, the development of several programming languages, such as FORTRAN, LISP and COBOL, started to address the double issue of portability—having a program run unmodified on different machines—and expressivity—expressing a program text in a high-level, English-like syntax, rather than Assembly instruction codes. Programmers are no longer tied to a specific machine, and therefore acquire a certain autonomy, a recognition which culminates in the naming of the field of software engineering (
Randell, 1996)
NATO Software Engineering Conference 1968 by Brian Randell, 1996. [link]
.
Campbell-Kelly concludes on a wave of mass-market production: following the advent of the UNIX family of operating systems, the distribution of the C programming language, the wide availability of C compilers, and the appearance of personal computers such as the Commodore 64, Altair and Apple II, software could be effectively entirely decoupled from hardware. The writing of software is no longer a corollary to the design of hardware, and as an independent field would as such become the main focus of computing as a whole (
author, year)
. And yet, software immediately enters a crisis, where projects run over time and budget, prove to be unreliable in production and unmaintainable in the long-run. It is at this time that discussions around best practices in writing source code started to emerge.
This need for a more formal approach to the actual process of programming found one of its most important manifestations in Edsger Dijkstra's Notes on Structured Programming (
author, year)
. In it, he argues for moving away from programming as a craft, and towards programming as an organized discipline, with its methodologies and systematization of program construction. Despite its laconic section titles8, Dijkstra's 1972 report nonetheless contributed to establish a more rigorous typology of the constructs required for reliable, provable programs—based on fundamental heuristics such as sequencing, selection, iteration and recursion—, and aimed at the formalization of the practice. Along with other subsequent developments (such as Hoare's contribution on proper data structuring (
author, year)
, or the rise of object-oriented programming with Smalltalk (
Kay, 1993)
The early history of Smalltalk by Alan C. Kay, 1993. [link]
) programming would solidify its foundations as a profession:
We knew how the nonprofessional programmer could write in an afternoon a three-page program that was supposed to satisfy his needs, but how would the professional programmer design a thirty-page program in such a way that he could really justify his design? What intellectual discipline would be needed? What properties could such a professional programmer demand with justification from his programming language, from the formal tool he had to work with? (
author, year)
As a result of such interrogations comes an industry-wide search for solutions to the intractable problem of programming: that it is a technique to manage information which in turn produces information . To address such a conundrum, a variety of tools, formal methods and management processes enter the market; they aim at acting as a silver bullet (
Brooks Jr, 1975)
The Mythical Man-month: Essays on Software Engineering by Frederick Phillips Brooks Jr, 1975. [link]
, a magical solution addressing the cascade of potential risks which emerge from large software applications9. This growth in complexity is also accompanied by a diversification of software applications: as computers become more widely available, and as higher-level programming languages provide more flexibility in their expressive abilities, software engineering engages with a variety of domains, each of which might need a specific solution, rather than a generic process. Confronted with this diversity of applications, business literature on software practices flourishes, being based on the assumption that the complexity of software should be tackled at its bottleneck: the reading and writing of source code.
The most recent wave in the history of software developers is the popularization of the Internet and of the World Wide Web, a network which was only standardized in 1982 and access to it was provided commercially in 1989. Built on top of the Internet, it popularized global information exchange, including technical resources to read and write code. Software could now be written on cloud computing platforms, shared through public repositories and deployed via containers with a lower barrier to entry than at a time of source code printed in magazines, of overnight batch processing and of non-time-sharing systems.
Engineering texts
Software developers have written some of the largest program texts to this date. However, due to its close ties to commercial distributors, source code written in this context often falls under the umbrella of proprietary software, thus made unavailable to the public. The program texts written by software developers are large, they often feature multiple programming languages and are highly structured and standardized: each file follows a pre-established convention in programming style, which supports an authoring by multiple programmers without any obvious trace to a single individual authorship. These program texts stand the closest to a programming equivalent of engineering, with its formalisms, standards, usability and attention to function.
The IEEE's Software Engineering Body of Knoweldge (SWEBOK) provides a good starting point to survey the specificities of software developers as source code writers and readers (
author, year)
; the main features of which include the definition of requirements, design, construction, testing and maintenance. Software requirements are the acknowledgement of the importance of the problem domain , the domain to which the software takes its inputs from, and to which it applies its outputs. For instance, software written for a calculator has arithmetic as its problem domain; software written for a learning management system has students, faculty, education and courses as its problem domain; software written a banking institution has financial transactions, savings accounts, fraud prevention and credit lines as its problem domain. This essential step in software development aims at formalizing as best as possible the elements that exist beyond software, in order to make those computable, and the design of an adequate formalism is a fundamental requirement for a successful software application.
Software design relates to the overall organization of the software components, considered not in their textual implementation, but in their conceptual agency. Usually represented through diagrams or modelling languages, it is concerned with understanding how a system should be organized and designing the overall structure of that system (
author, year)
. Of particular interest is the relationship that is established between software development and software architecture. Software architecture operates both from a top-down perspective, laying down an abstract blueprint for the implementation of a system and dictating how a program text is structured, how its parts interact, why it's built that way, consisting different components of an existing system interact (
Brown, 2011)
Introduction by Amy Brown, Greg Wilson, 2011. [link]
.
Software construction relates to the actual writing of software, and how to do so in the most reliable way possible. The SWEBOK emphasizes first and foremost the need to minimize complexity10, in anticipation of likely changes and possible reuse by other software systems. Here, the emphasis on engineering is particularly salient: while most would refer to the creation of software as writing software, the IEEE document refers to it as constructing software: the creation of working software through a combination of coding, verification, unit testing, integration testing, and debugging. (
author, year)
. The practice of software engineers thus implements functional and reliable mechanical designs through, ultimately, the act of writing in formal languages.
Software maintenance, finally, relates not to the planning or writing of software, but to its reading. Software is notoriously filled with bugs11which can be fixed through the release of software updates. This means that the life of a software doesn't stop when its first version is written, but rather when it does not run anywhere anymore: it can still be edited across time and space, by other programmers which might not have access to the original group of implementers: consequently, software should be first and foremost understandable—SWEBOK lists the first feature of coding as being techniques for creating understandable source code (
author, year)
. This final component of software development directs us back to its notorious cognitive complexity, one that increases with the age of the software.
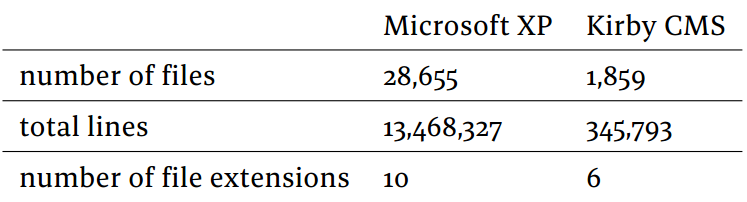
What does this look like in practice? In order to understand the aesthetic preferences of software developers, we must start by assessing the kinds of program texts they write. We look at excerpts from two code bases: the source code for Microsoft Windows XP, which was started in 2001 (
Warren, 2020)
Windows XP source code leaks online by Tom Warren, 2020. [link]
, and the Kirby CMS project, started in 2011; the quantitative specificities of both code bases are shown inms-kirby
. While these two projects differ drastically in their size, in their age, and in the number of developers involved in their creation and maintenance, we nonetheless choose them as the respective ends of a single spectrum of software engineering. In both cases, the prime concern is with function and maintainability.
ms-kirby
Table comparing the scale of two software development projects.
First, the most striking visual feature of the code is its sheer size. In the case of Microsoft XP, representing such a versatile and low-level application such as an operating system results in files that are often above 2000 lines of code. In order to allow abstraction techniques at a higher-level for the end-developer, the operating system needs to do a significant amount of "grunt" work, relating directly to the concrete reality of the hardware platform which needs to be operated on. Looking at the file cmdatini.c
, reproduced partially in
ms2000
{
ULONG i;
RtlInitUnicodeString(&CmRegistryRootName,
CmpRegistryRootString);
RtlInitUnicodeString(&CmRegistryMachineName,
CmpRegistryMachineString);
RtlInitUnicodeString(&CmRegistryMachineHardwareName,
CmpRegistryMachineHardwareString);
RtlInitUnicodeString(&CmRegistryMachineHardwareDescriptionName,
CmpRegistryMachineHardwareDescriptionString);
RtlInitUnicodeString(&CmRegistryMachineHardwareDescriptionSystemName,
CmpRegistryMachineHardwareDescriptionSystemString);
RtlInitUnicodeString(&CmRegistryMachineHardwareDeviceMapName,
CmpRegistryMachineHardwareDeviceMapString);
RtlInitUnicodeString(&CmRegistryMachineHardwareResourceMapName,
CmpRegistryMachineHardwareResourceMapString);
// ...//// Initialize the type names for the hardware tree.//
for (i = 0; i <= MaximumType; i++)
{
RtlInitUnicodeString(&(CmTypeName[i]),
CmTypeString[i]);
}
// ...
return;
}
- Unicode string initialization in Microsoft 2000 operating system, with a first part showing an explicit repeating pattern, while the second part shows a more compressed approach.
, we see very long variable names, with a rhythmic, repetitive structure where differences between lines is not obivous at first.
ms2000
{
ULONG i;
RtlInitUnicodeString(&CmRegistryRootName,
CmpRegistryRootString);
RtlInitUnicodeString(&CmRegistryMachineName,
CmpRegistryMachineString);
RtlInitUnicodeString(&CmRegistryMachineHardwareName,
CmpRegistryMachineHardwareString);
RtlInitUnicodeString(&CmRegistryMachineHardwareDescriptionName,
CmpRegistryMachineHardwareDescriptionString);
RtlInitUnicodeString(&CmRegistryMachineHardwareDescriptionSystemName,
CmpRegistryMachineHardwareDescriptionSystemString);
RtlInitUnicodeString(&CmRegistryMachineHardwareDeviceMapName,
CmpRegistryMachineHardwareDeviceMapString);
RtlInitUnicodeString(&CmRegistryMachineHardwareResourceMapName,
CmpRegistryMachineHardwareResourceMapString);
// ...//// Initialize the type names for the hardware tree.//
for (i = 0; i <= MaximumType; i++)
{
RtlInitUnicodeString(&(CmTypeName[i]),
CmTypeString[i]);
}
// ...
return;
}
- Unicode string initialization in Microsoft 2000 operating system, with a first part showing an explicit repeating pattern, while the second part shows a more compressed approach.
The repetition of the RtlInitUnicodeString
in the first part of this listing stands at odds with the second part of the code, the for()
statement, displaying a contrast between between a verbose text and a compressed text. Verbosity, the act of explicitly writing out statements which could be functionally equivalent in a compacted form, is a feature of the Windows 2000 codebase, one which is a consequence of a particular problem domain, of a particular business imperative of maintainability, and of the particular semantic environment of the C programming language.
The problem domain of the Windows XP operating system, its longevity and its update cycle, all contribute to its complexity and have affected how this code is written. Here, the problem domain of the program text is the computer hardware, and its function is to make sure the kernel knows about the hardware it is running on (e.g. its name, its description, etc.), in an explicit and verbose way, before more compressed writing techniques can be used. Dealing with a specific problem domain (i.e. kernel instructions) leads to a specific kind of aesthetics; here, forcing the programmers to repeat references to RtlInitUnicodeString()
1580 times across 336 files.
Another significant aesthetic feature of the Windows 2000 program text is its use of comments, and how those comments point to a collaborative, layered authorship. This particular program text is written across individuals and across time, each with presumably its own approach. Yet, writing source code within a formal organization often implies the harmonization of individual approaches, and thus the adoption of coding styles, with the intent that all code in any code-base should look like a single person typed it, no matter how many people contributed (
Waldron, 2020)
Idiomatic.js/readme.md at master · rwaldron/idiomatic.js by Rick Waldron, 2020. [link]
. The excerpt in
buffer_c
no_more_data :
// There should be enough bits still left in the data segment;// if so, just break out of the outer while loop.if (bits_left >= nbits) break;
/* Uh-oh. Report corrupted data to user and stuff zeroes into
* the data stream, so that we can produce some kind of image.
* Note that this code will be repeated for each byte demanded
* for the rest of the segment. We use a nonvolatile flag to ensure
* that only one warning message appears.
*/if (!*(state->printed_eod_ptr))
{
WARNMS(state->cinfo, JWRN_HIT_MARKER);
*(state->printed_eod_ptr) = TRUE;
}
c = 0; // insert a zero byte into bit buffer
}
}
/* OK, load c into get_buffer */
get_buffer = (get_buffer << 8) | c;
bits_left += 8;
}
/* Unload the local registers */
state->next_input_byte = next_input_byte;
state->bytes_in_buffer = bytes_in_buffer;
state->get_buffer = get_buffer;
state->bits_left = bits_left;
return TRUE;
}
- Overlapping programming voices can be hinted at by different comment styles.
from jdhuff.c
is a example of such overlapping of styles.
buffer_c
no_more_data :
// There should be enough bits still left in the data segment;// if so, just break out of the outer while loop.if (bits_left >= nbits) break;
/* Uh-oh. Report corrupted data to user and stuff zeroes into
* the data stream, so that we can produce some kind of image.
* Note that this code will be repeated for each byte demanded
* for the rest of the segment. We use a nonvolatile flag to ensure
* that only one warning message appears.
*/if (!*(state->printed_eod_ptr))
{
WARNMS(state->cinfo, JWRN_HIT_MARKER);
*(state->printed_eod_ptr) = TRUE;
}
c = 0; // insert a zero byte into bit buffer
}
}
/* OK, load c into get_buffer */
get_buffer = (get_buffer << 8) | c;
bits_left += 8;
}
/* Unload the local registers */
state->next_input_byte = next_input_byte;
state->bytes_in_buffer = bytes_in_buffer;
state->get_buffer = get_buffer;
state->bits_left = bits_left;
return TRUE;
}
- Overlapping programming voices can be hinted at by different comment styles.
Comments are specific lines of source code, identified by particular characters (in the C programming language, they are marked using //
and /* */
), which are ignored by the machine. That is, they are only expected to be read by other programmers, and in this case primarily by programmers belonging to a single business organization. Here, the variety of comment characters and the variety of capitalization hint at the various origins of the authors, or at the very least at the different moments, and possible mental states of the potential single-author.
Treated as natural language, comments are not procedurally guaranteed to be reflected in the execution, of the program, and are considered by some as misleading: they might be saying something, while the code does something else12. Beyond the presence of multiple authors, this excerpt also exemplifies the tension between source code as the canonical source of knowledge of what the program does and how it does it and comments as a more idiosyncratic dimension of all natural-language expressions of human programmers.
And yet, this chronological and interpersonal spread of the program text, combined with organizational practices, require the use of comments in order to maintain aesthetic and cognitive coherence in the program. This is the case in the use of comment headers, which locate a specific file within the greater architectural organization of the program text (see
- This listing shows the explicit traces of multiple authors collaborating on a single file over time.
). This highlights the multiple authors and the evolution in time of the file: comments are the only manifestation of this layering of revisions which ultimately results in the "final" software13.
- This listing shows the explicit traces of multiple authors collaborating on a single file over time.
Ultimately, the Windows XP source code shows some of the components at stake in the program texts written by software developers: verbosity and compression, multi-auctoriality, and natural language writing in the midst of formal languages. Still, as an operating system developed by one of the largest corporations in the world, it also possesses some specificities due to its problem domain, programming language and socio-economic environment.
Another example of a program text written by software developers, complementing Windows XP, is the Kirby CMS (
Allgeier, 2022)
. With development starting in 2011 and a first release in 2012, it developed a steady community of users, shown in consistent forum posts and commit history on the main repository. Kirby is open-source content management system, meaning that it affords direct engagement of other developers with its architecture through modification, extension or partial replacement. Its problem domain is therefore the organization of user-facing multimedia assets, such as text, images and videos.
The Kirby source code is entirely available online, and the following snippets hint at another set of formal values—conciseness, expliciteness and delimitation. Conciseness can be seen in the lengths of the various components of the code base. For instance, the core of Kirby consists in 1859 files, with the longest being src/Database/Query.php
at 1065 lines, and the shortest being src/Http/Exceptions/NextRouteException.php
at 16 lines, for an average of 250 lines per file14.
If we look at a typical function declaration within Kirby, we found one such as the distinct()
setter for Kirby's database, reproduced in
Out of these 11 lines, the actual functionality of the function is focused on one line, $this->distinct = $distinct;
. Around it are machine-readable comment snippets, and a function wrapper around the simple variable setting. The textual overhead then comes from the wrapping itself: the actual semantic task of deciding whether a query should be able to include distinct select clauses (as opposed to only allowing join clauses), is now decoupled from its actual implementation. The quality of this writing, at first verbose, actually lies in its conciseness in relation to the possibilities for extension that such a form of writing allows: the distinct()
function could, under other circumstances, be implemented differently, and still behave similarly from the perspective of the rest of the program. Additionally, this wrapping enables the setting of default values (here, true
), a minimal way to catch bugs by always providing a fallback case.
Kirby's source code is also interestingly explicit in comments, and succint in code. Taking from the Http\\Route
class, reproduced in
route_php
/**
* Tries to match the path with the regular expression and
* extracts all arguments for the Route action
*
* @param string $pattern
* @param string $path
* @return array|false
*/publicfunctionparse(string$pattern, string$path)
{
// check for direct matchesif ($pattern === $path) {
return$this->arguments = [];
}
// We only need to check routes with regular expression since all others// would have been able to be matched by the search for literal matches// we just did before we started searching.if (strpos($pattern, '(') === false) {
returnfalse;
}
// If we have a match we'll return all results// from the preg without the full first match.if (preg_match('#^' . $this->regex($pattern) . '$#u', $path, $parameters)) {
return$this->arguments = array_slice($parameters, 1);
}
returnfalse;
}
- The inclusion of comments help guide a programmer through an open-source project .
(
Allgeier, 2021)
, we can see a different approach to comments than in
buffer_c
no_more_data :
// There should be enough bits still left in the data segment;// if so, just break out of the outer while loop.if (bits_left >= nbits) break;
/* Uh-oh. Report corrupted data to user and stuff zeroes into
* the data stream, so that we can produce some kind of image.
* Note that this code will be repeated for each byte demanded
* for the rest of the segment. We use a nonvolatile flag to ensure
* that only one warning message appears.
*/if (!*(state->printed_eod_ptr))
{
WARNMS(state->cinfo, JWRN_HIT_MARKER);
*(state->printed_eod_ptr) = TRUE;
}
c = 0; // insert a zero byte into bit buffer
}
}
/* OK, load c into get_buffer */
get_buffer = (get_buffer << 8) | c;
bits_left += 8;
}
/* Unload the local registers */
state->next_input_byte = next_input_byte;
state->bytes_in_buffer = bytes_in_buffer;
state->get_buffer = get_buffer;
state->bits_left = bits_left;
return TRUE;
}
- Overlapping programming voices can be hinted at by different comment styles.
of Microsoft XP operating system.
route_php
/**
* Tries to match the path with the regular expression and
* extracts all arguments for the Route action
*
* @param string $pattern
* @param string $path
* @return array|false
*/publicfunctionparse(string$pattern, string$path)
{
// check for direct matchesif ($pattern === $path) {
return$this->arguments = [];
}
// We only need to check routes with regular expression since all others// would have been able to be matched by the search for literal matches// we just did before we started searching.if (strpos($pattern, '(') === false) {
returnfalse;
}
// If we have a match we'll return all results// from the preg without the full first match.if (preg_match('#^' . $this->regex($pattern) . '$#u', $path, $parameters)) {
return$this->arguments = array_slice($parameters, 1);
}
returnfalse;
}
- The inclusion of comments help guide a programmer through an open-source project .
(
Allgeier, 2021)
The 9 lines above the function declaration are machine-readable documentation. It can be parsed by a programmatic system and used as input to generate more classical, human-readable documentation in the form of a website or a printed document. This is noticeable due to the highly formalized syntax param string name_of_var
, rather than writing out "this function takes a parameter of type string named name_of_var
". This does compensate for the tendency of comments to drift out of synchronicity with the code that they are supposed to comment, by tying them back to some computational system to verify its semantic contents, while providing information about the inputs and outputs of the function. Once again, we see that the source of truth is the computer's ability of reading input and executing it.
Beyond expliciting inputs and outputs, the second aspect of these comments is targeted at the how of the function, helping the reader understand the rationale behind the programmatic process. Comments here aren't cautionary notes on specific edge-cases, as seen in
route_php
/**
* Tries to match the path with the regular expression and
* extracts all arguments for the Route action
*
* @param string $pattern
* @param string $path
* @return array|false
*/publicfunctionparse(string$pattern, string$path)
{
// check for direct matchesif ($pattern === $path) {
return$this->arguments = [];
}
// We only need to check routes with regular expression since all others// would have been able to be matched by the search for literal matches// we just did before we started searching.if (strpos($pattern, '(') === false) {
returnfalse;
}
// If we have a match we'll return all results// from the preg without the full first match.if (preg_match('#^' . $this->regex($pattern) . '$#u', $path, $parameters)) {
return$this->arguments = array_slice($parameters, 1);
}
returnfalse;
}
- The inclusion of comments help guide a programmer through an open-source project .
(
Allgeier, 2021)
, or on generic meta-information, but rather natural language renderings of the thought process of the programmer. The implication here is to provide a broader, and more explicit understanding of the process of the function, in order to allow for further maintenance, extension or modification.
Finally, we look at a subset of the function, the clause of the third if-statement: (preg_match('#^' . $this->regex($pattern) . '$#u', $path, $parameters))
. Without comments, one must rely on cognitive gymnastics and knowledge of the PHP syntax in order to render this as an extraction of all route parameters, implying the removal of the first element of the array. In this sense, then, Kirby's code for parsing an HTTP route is both verbose in comments and parsimonious in code. The reason for those comments becomes clear: that the small core of the function is actually hard to understand.
Looking at some excerpts from the Kirby program texts, we see a small number of files, overall short file length, short function length, consistent natural language comments and concise functionality. These aesthetic features give an impression of building blocks: short, graspable, (re-)usable components are made available to the developer directly, as the open-source project relies on contributions from individuals who are not expected to have any other encounter with the project other than, at the bare minimum, the source code itself.
clipboard_js
// fall back to little execCommand hack with a temporary textareaconstinput = document.createElement("textarea");
input.value = value;
document.body.append(input);
- Even in a productive and efficient open-source project, one can detect traces of "hacks" .
(
Allgeier, 2021)
In conclusion, these two examples of program texts written by software developers, Microsoft Windows XP and Kirby CMS, show particular presentations of source code—such as repetition, verbosity, commenting and conciseness. These are in part tied to their socio-technical ecosystems made up of hardware, institutional practices ranging from corporate guidelines to open-source contribution, with efficiency and usability remaining at the forefront, at least in its executed form.
Indeed, software developers are a large group of practitioners whose focus is on producing effective, reliable and sustainable software. This leads them to writing in a relatively codified manner. And yet, we must acknowledge that idiosyncracies in source code emerge; in
clipboard_js
// fall back to little execCommand hack with a temporary textareaconstinput = document.createElement("textarea");
input.value = value;
document.body.append(input);
- Even in a productive and efficient open-source project, one can detect traces of "hacks" .
(
Allgeier, 2021)
, a function handling text input uses a convoluted workaround to store text data. Even in business environments and functional tools, then, the hack is never too far. The boundary between groups of practitioners is not clear-cut, and so we now turn to the correlated practice of hackers.
Hackers
To hack, in the broadest sense, is to enthusiastically inquire about the possibilities of exploitation of technical systems15. Computer hacking specifically came to proeminence as early computers started to become available in north-american universities, and coalesced around the Massachussets Institute of Technology's Tech Model Railroad Club (
author, year)
. Computer hackers were at the time skilled and highly-passionate individuals, with an autotelic inclination to computer systems: these systems mattered most when they referenced themselves, instead of interfacing with a given problem domain. Early hackers were often self-taught, learning to tinker with computers while still in high-school (
Lammers, 1986)
Programmers at work : interviews by Susan M. Lammers, 1986. [link]
, and as such tend to exhibit a radical position towards expertise: skill and knowledge aren't derived from academic degrees or credentials, but rather from concrete ability and practical efficacy16.
The histories of hacking and of software development are deeply intertwined: some of the early hackers worked on software engineering projects—such as the graduate students who wrote the Apollo Guidance Computer routines under Margaret Hamilton—and then went on to profoundly shape computer infrastructure. Particularly, the development of the UNIX operating system by Dennis Ritchie and Ken Thompson is a key link in connecting hacker practices and professional ones. Developed from 1969 at Bell Labs, AT&T's research division, UNIX was a product at the intersection of corporate and hacker culture, built by a small team, circulating along more or less legal channels, and spreading its design philosophy of clear, modular, simple and transparent design across programming communities (
author, year)
.
Hacker culture built on this impetus to share source code, and hence to make written software understandable from its textual manifestation. After hardware stopped being the most important component of a computing system, the shift to focusing on software development had led manufacturers to stop distributing source code, making proprietary software the norm. Until then, executable software was the consequence of running the source code through a compilation process; around the 1980s, executable software was distributed directly as a binary file, its exact contents an unreadable series of 0s and 1s.
In the meantime, personal microcomputers came to the market and opened up this ability to tinker and explore computer systems beyond the realms of academic-licensed large mainframes and operating systems. Starting with models such as the Altair 8800, the Apple II and the Commodore 64, as well as with easier, interpreted computer languages such as BASIC, whose first version for such micro-computers was written by Bill Gates, Paul Allen and Monte Davidoff (
Montfort, 2014)
10 PRINT CHR$(205.5+RND(1)); : GOTO 10 by Nick Montfort, Patsy Baudoin, John Bell, Ian Bogost, Jeremy Douglass, 2014.
. While seemingly falling out of the realm of "proper" programming, the microcomputer revolution allowed for new groups of individuals to explore the interactivity of source code due to their small size when published as type-in listings.
In the wake of the larger free software movement, emerged its less radical counterpart, the open-source movement, as well as its more illegal counterpart, security hacking. The latter is usually represented by the types of individuals depicted in mainstream news outlets when they reference hackers: programmers breaching private systems, sometimes in order to cause financial, intelligence or material harm. Security hackers, sometimes called crackers, form a community of practice of their own, with ideas of superior intelligence, subversion, adventure and stealth17. These practices nonetheless refer to the original conception of hacking—getting something done quickly, and well—and include such a practical, efficient appoach into its own set of values and ideals. In turn, these are represented in the kinds of program texts being written by members of this community of practice.
Meanwhile, the open-source movement took the tenets of hacking culture and adapted it to make it more compatible to the requirements of businesses. Indeed, beyond the broad values of intellectual curiosity and skillful exploration, free software projects such as the Linux kernel, the Apache server or the OpenSSL project have proven to be highly efficient, and used in both commercial, non-commercial, critical and non-critical environments (
author, year)
. Such an approach sidesteps the political and ethical values held in previous iterations of the hacker ethos in order to focus exclusively on the sharing of source code and open collaboration while remaining within an inquisitive and productive mindframe. With the advent of corporate hackathons —short instances of intense collaboration in order to create new software, or new features on a software system—are a particularly salient example of this overlap between industry practices and hacker practices (
Nolte, 2018)
You Hacked and Now What? - Exploring Outcomes of a Corporate Hackathon by Alexander Nolte, Ei Pa Pa Pe-Than, Anna Filippova, Christian Bird, Steve Scallen, James D. Herbsleb, 2018. [link]
18.
As a community of practice, hackers are programmers which, while overlapping with industry-embedded software developers, hold a set of values and ideals regarding the purpose and state of software. Whether academic hackers, amateurs, security hackers or open-source contributors, all are centered around the object of source code as a vehicle for communicating the knowledge held within the software, the necessity of skill for writing such software, and a certain inclination towards "quick and dirty" solutions.
Program texts as puzzles
Incidentally, those political and ethical values of expertise and openness often overlap with aesthetic values informing how their code exists in its textual manifestation. By looking at a few program texts written by hackers, we will see how their skillful engagment with the machine, and their playful stances towards solving problems is also reflected in how they write source code.
To hack is, according to the dictionary, "to cut irregularly, without skill or definite purpose; to mangle by or as if by repeated strokes of a cutting instrument". I have already said that the compulsive programmer, or hacker as he calls himself, is usually a superb technician. It seems therefore that he is not "without skill" as the definition will have it. But the definition fits in the deeper sense that the hacker is "without definite purpose": he cannot set before him a clearly defined long-term goal and a plan for achieving it, for he has only technique, not knowledge. He has nothing he can analyze or synthesize; in short, he has nothing to form theories about. His skill is therefore aimless, even disembodied. It is simply not connected with anything other than the instrument on which it may be exercised. His skill is that of a monastic copyist who, though illiterate, is a first rate calligrapher. (
author, year)
Weizenbaum's perspective is that of a computer scientist whose theoretical work can be achieved only through thought, pen and paper. As such, he looks down on hackers as experts who can get lost in technology for its own sake. Gabriella Coleman, in her anthropological study of hackers, highlights that they value both semantic ingenuity19and technical wittiness (
author, year)
. Source code written by hackers can take multiple shapes, from one-liners, to machine language magic and subversion of best practices in crucial moments.
The one-liner is a piece of source code which fits on one line, and is usually intepreted immediately by the operating system. They are terse, concise, and eminently functional: they accomplish one task, and one task only. This binary requirement of efficiency finds a parallel in a different kind of one-liners, the jokes of stand-up comedy. In this context, the one-liner also exhibits the features of conciseness and impact, with the setup conflated with the punch line, within the same sentence. One-liners are therefore self-contained, whole semantic statements which, through this syntactic compression, appear to be clever. In order to understand how compression occurs in program texts, we can look at the difference between
- This program text selects all the lines from an input file which is longer than 6 characters in the C programming language. See the one-line alternative implementation in .
and
select_lines_awk
awk'$3 > 6' data.txt
- This program text selects all the lines from an input file which is longer than 6 characters in the C programming language, in just one line of code. See the alternative implementation in 20 lines of code in .
. Both of these have the same functionality: they select all the lines of a given input file.
- This program text selects all the lines from an input file which is longer than 6 characters in the C programming language. See the one-line alternative implementation in .
- This program text selects all the lines from an input file which is longer than 6 characters in the C programming language. See the one-line alternative implementation in .
, achieving this functionality using the C programming language takes 20 lines. The equivalent in the AWK scripting language takes a single line, a line which the author actually refers to in a comment in
- This program text selects all the lines from an input file which is longer than 6 characters in the C programming language. See the one-line alternative implementation in .
, presumably as a personal heuristic as he is writing the function. The difference is obvious, not just in terms of formal clarity and reduction of the surface structure, but also in terms of matching the problem domain: this says that it prints every line in which the third field is greater than 6, and is easier to read, even for non-expert programmers. The AWK one-liner is more efficient, more understandable because it allows for less confusion while also reducing the amount of text necessary, and thus ultimately considered to be fitter to the task at hand.
select_lines_awk
awk'$3 > 6' data.txt
- This program text selects all the lines from an input file which is longer than 6 characters in the C programming language, in just one line of code. See the alternative implementation in 20 lines of code in .
In programming, one-liners have their roots in the philosophy of the UNIX operating system, as well as in the early diffusion of computer programs for personal computer hobbyists (
Montfort, 2014)
10 PRINT CHR$(205.5+RND(1)); : GOTO 10 by Nick Montfort, Patsy Baudoin, John Bell, Ian Bogost, Jeremy Douglass, 2014.
. On the one side, the Unix philosophy is fundamentally about building simple tools, which all do one thing well, in order to manipulate text streams (
author, year)
, and each of these tools can then be composed in order to produce complex results—a feature of programming languages we will discuss inProgramming languages
. Sometimes openly acknowledged by language designers—such as those of AWK—the goal is to write short programs which shouldn't be longer than one line. Given that constraint, a hacker's response would then be: how short can you make it?
Writing the shortest of all programs does become a matter of skill and competiton, coupled with a compulsivity to reach the most syntactically compressed version20.
This behaviour is also manifested in the practice of code golf , challenges in which programmers must solve problems by using the least possible amount of character21, or in contests such as the Mathematica One-Liner Competition (
Carlson, 2010)
The Mathematica One-Liner Competition—Wolfram Blog by Christopher Carlson, 2010. [link]
. Minimizing program length in relation to the problem complexity is therefore a definite feature of one-liners, since choosing the right programming language for the right tasks can lead to a drastic reduction of syntax, while keeping the same expressive and effective power.
On the other hand, however, one-liners can be so condensed that they loose all sense of clarity for a reader who does not have a deep knowledge of the language in which it is written, or of the problem being solved. For instance,
game_of_life
life ← {⊃1 ⍵ ∨.∧ 34 = +/ +⌿ ¯101 ∘.⊖ ¯101 ⌽¨ ⊂⍵}
- Conway's Game of Life implemented in APL is a remarkable example of conciseness, at the expanse of readability.
is an implementation of Conway's game of life implemented in one line of the APL programming. Conway's Game of Life is a well-known simulation where a small set of initial conditions and rules for evolution produce unexpected emergent complexity. Its combination with APL programming language, which makes an extensive use of symbolic graphical characters to denote functions and operations, leads to particularly dense and terse source code.
game_of_life
life ← {⊃1 ⍵ ∨.∧ 34 = +/ +⌿ ¯101 ∘.⊖ ¯101 ⌽¨ ⊂⍵}
- Conway's Game of Life implemented in APL is a remarkable example of conciseness, at the expanse of readability.
This particular example shows why one-liners are usually highly discouraged for any sort of code which needs to be worked on by other programmers. Cleverness in programming tends to be seen as a display of the relationship between the programmer, the language and the machine, rather than between different programmers. On the other hand, the small nature of one-liners makes them highly portable and shareable. Popular with early personal computer adopters, at a time during which the source code of programs were printed in hobbyist magazines and needed to be input by hand, and during which access to computation wasn't widely distributed amongst society, being able to type just one line in a computer program, and resulting in unexpected graphical patterns created a sense of magic and wonder in first-time users22, surprised by how so little can do so much (
Montfort, 2014)
10 PRINT CHR$(205.5+RND(1)); : GOTO 10 by Nick Montfort, Patsy Baudoin, John Bell, Ian Bogost, Jeremy Douglass, 2014.
.
Another quality of hacker code is the idiosyncratic solution to an intricate puzzle. The listing in
fast_sqrt_c
floatQ_rsqrt(float number){
long i;
float x2, y;
constfloat threehalfs = 1.5F;
x2 = number * 0.5F;
y = number;
i = *(long *)&y; // evil floating point bit level hacking
i = 0x5f3759df - (i >> 1); // what the fuck?
y = *(float *)&i;
y = y * (threehalfs - (x2 * y * y)); // 1st iteration// y = y * ( threehalfs - ( x2 * y * y ) ); // 2nd iteration,// this can be removedreturn y;
}
- This particular implementation of a function calculating the inverse square root of a number has become known in programming circles for both its speed and unscrutability.
calculates the inverse square root of a given number, a routine but computationally expensive calculation need in computer graphics. It was found in the source code of id Software's Quake video game23.
fast_sqrt_c
floatQ_rsqrt(float number){
long i;
float x2, y;
constfloat threehalfs = 1.5F;
x2 = number * 0.5F;
y = number;
i = *(long *)&y; // evil floating point bit level hacking
i = 0x5f3759df - (i >> 1); // what the fuck?
y = *(float *)&i;
y = y * (threehalfs - (x2 * y * y)); // 1st iteration// y = y * ( threehalfs - ( x2 * y * y ) ); // 2nd iteration,// this can be removedreturn y;
}
- This particular implementation of a function calculating the inverse square root of a number has become known in programming circles for both its speed and unscrutability.
What we see here is a combination of the understanding of the problem domain (i.e. the acceptable result needed to maintain a high-framerate with complex graphics), the specific knowledge of low-level computers operations (i.e. bit-shifting of a float cast as an integer) and the snappiness and wonder of the comments24. The use of 0x5f3759df
is what programmers call a magic number , a literal value whose role in the code isn't made clearer by a descriptive variable name. Usually bad practice and highly-discouraged, the magic number here is exactly that: it makes the magic happen. Paradoxically, the author Greg Walsh displays a very deep knowledge of how IEEE standards represent floating point numbers, to the extent that he is able to bend such standards into productive edge cases. While it is obvious what the program text does, it is extremely difficult to understand how.
This playfulness at writing things that do not do what it seems like they do is another aspect of hacker culture. The Obfuscated C Code Contest, starting in 1984, is the most popular and oldest organized production of such code, in which programmers submit code that is functional and visually meaningful beyond the exclusive standards of well-formatted code. Obfuscated code is a first foray into closely intertwining these separate meanings in the source code itself, making completely opaque what the code does, and inviting the reader to decipher it.
circle_c
#define_ -F<00||--F-OO--;
int F=00,OO=00;main(){F_OO();printf("%1.3f\n",4.*-F/OO/OO);}F_OO()
{
_-_-_-__-_-_-_-_-_-_-_-__-_-_-_-_-_-_-_-_-_-_-__-_-_-_-_-_-_-_-_-_-_-_-_-__-_-_-_-_-_-_-_-_-_-_-_-_-_-__-_-_-_-_-_-_-_-_-_-_-_-_-_-__-_-_-_-_-_-_-_-_-_-_-_-_-_-_-__-_-_-_-_-_-_-_-_-_-_-_-_-_-_-__-_-_-_-_-_-_-_-_-_-_-_-_-_-_-__-_-_-_-_-_-_-_-_-_-_-_-_-_-_-__-_-_-_-_-_-_-_-_-_-_-_-_-_-__-_-_-_-_-_-_-_-_-_-_-_-_-_-__-_-_-_-_-_-_-_-_-_-_-_-_-__-_-_-_-_-_-_-_-_-_-_-__-_-_-_-_-_-_-__-_-_-_
}
- Entry to the 1988 IOCCC, it computes an approximation of $ $ by calculating the circumference of a circle drawn as text.
(
Westley, 1988)
The International Obfuscated C Code Contest Winners 1988 by Brian Westley, 1988. [link]
The source code in
circle_c
#define_ -F<00||--F-OO--;
int F=00,OO=00;main(){F_OO();printf("%1.3f\n",4.*-F/OO/OO);}F_OO()
{
_-_-_-__-_-_-_-_-_-_-_-__-_-_-_-_-_-_-_-_-_-_-__-_-_-_-_-_-_-_-_-_-_-_-_-__-_-_-_-_-_-_-_-_-_-_-_-_-_-__-_-_-_-_-_-_-_-_-_-_-_-_-_-__-_-_-_-_-_-_-_-_-_-_-_-_-_-_-__-_-_-_-_-_-_-_-_-_-_-_-_-_-_-__-_-_-_-_-_-_-_-_-_-_-_-_-_-_-__-_-_-_-_-_-_-_-_-_-_-_-_-_-_-__-_-_-_-_-_-_-_-_-_-_-_-_-_-__-_-_-_-_-_-_-_-_-_-_-_-_-_-__-_-_-_-_-_-_-_-_-_-_-_-_-__-_-_-_-_-_-_-_-_-_-_-__-_-_-_-_-_-_-__-_-_-_
}
- Entry to the 1988 IOCCC, it computes an approximation of $ $ by calculating the circumference of a circle drawn as text.
(
Westley, 1988)
The International Obfuscated C Code Contest Winners 1988 by Brian Westley, 1988. [link]
, submitted to the 1988 IOCCC is a procedure which does exactly what it shows: it deals with a circle. More precisely, it estimates the value of PI by computing its own circumference. While the process is far from being straightforward, relying mainly on bitwise arithmetic operations and a convoluted preprocessor definition, the result is nonetheless very intuitive—the same way that PI is intuitively related to PI. The layout of the code, carefully crafted by introducing whitespace at the necessary locations, doesn't follow any programming practice of indentation, and would probably be useless in any other context, but nonetheless represents another aspect of the concept behind the procedure described, not relying on traditional programming syntax25, but rather on an intuitive, human-specific understanding26.
Obfuscating practices, beyond their technical necessities (for security and efficiency), are traditionally tied to hacking practices, prominently with one-liners (the shorter a name, the more obscure and general it becomes). As such, they rely on the brain-teasing process of deciphering, and on the pleasurable, aesthetic experience of resolving and uniting two parallel meanings: what we see in the code, and what it does27. What we focus on here is the aspect of obfuscation which plays with the different layers of meaning: meaning to the computer, meaning to the human, and different ways of representing and communicating this meaning (from uglifying, to consistent formatting, to depicting a circle with dashes and underscores). While the aesthetics at play in hacking will be further explored below, we focus on the fact that obfuscating code practices, beyond hiding the meaning and the intent of the program, also manifest an attempt to represent such a meaning in different ways. As such, it leaves aside traditional code-writing practices and suggests the meaning of the program by challenging the abilities of human interpretation at play in the process of deciphering programs.
Building on the fact that source code very often does not do what one thinks it does when executed, initiatives such as the Underhanded C Code contest have leaned to this tendency. In this contest, one " must write C code that is as readable, clear, innocent and straightforward as possible, and yet it must fail to perform at its apparent function. To be more specific, it should perform some specific underhanded task that will not be detected by examining the source code. " (
Craver, 2015)
The Underhanded C Contest » About by Scott Craver, 2015. [link]
. Hackers find value in this kind of paradigm-shifting: if software developers spend time attempting to make faulty, complex code easy to grasp and reliable, hackers would rather spend effort and skill making faulty code look deliberately functional.
Such intimate knowledge of both the language and the machine can be found in the program texts of the demoscene . Starting in Europe in the 1980s, demos were first short audio-visual programs which were distributed along with crackware (pirated software), and to which the names of the people having cracked the software were prepended, in the form of a short animation (
author, year)
. Due to this very concrete constraint—there was only so much memory left on a pirated disk to fit such a demo—programmers had to work with these limitations in order to produce the most awe-inspiring graphics effects before software boot. One notable feature of the demoscene is that the output should be as impressive as possible, as an immediate, phenomenological appreciation of the code which could make this happen, within a fixed technical constraint28. Indeed, the comp.sys.ibm.pc.demos
news group states in their FAQ:
A Demo is a program that displays a sound, music, and light show, usually in 3D. Demos are very fun to watch, because they seemingly do things that aren't possible on the machine they were programmed on.Essentially, demos "show off". They do so in usually one, two, or all three of three following methods:
They show off the computer's hardware abilities (3D objects, multi-channel sound, etc.)
They show off the creative abilities of the demo group (artists, musicians)
They show off the programmer's abilities (fast 3D shaded polygons, complex motion, etc.)
This showing off, however, does not happen through immediate engagement with the code from the reader's part, but rather in the thorough explanation of the minute functionalities of the demo by its writer. Because of these constraints of size, the demos are usually written in C, openGL, Assembly, or the native language of the targeted hardware. Source code listings of demos also make extensive use of shortcuts and tricks, and little attention is paid to whether or not other humans would directly read the source—the only intended recipient is a very specific machine (e.g. Commodore 64, Amiga VCS, etc.). The release of demos, usually in demoparties, are sometimes accompanied by documentation, write-ups or presentations. However, this presentation format acknowledges a kind of individual, artistic feat, rather than a collaborative, explicit text which tends to be preferred by software developers.
Pushing the boundaries of how much can be done in how little code,
a_mind_is_born
The annotated representation of the compiled version of A Mind Is Born, a demo by Linus Åkesson. The different color overlays highlight the meaningful regions of the program
(
author, year)
shows a 256-bytes demo resulting in a minute-long music video (
author, year)
on the Commodore 64. It is first listed as a hexademical dump by its author, without the original Assembly code29.
a_mind_is_born
The annotated representation of the compiled version of A Mind Is Born, a demo by Linus Åkesson. The different color overlays highlight the meaningful regions of the program
(
author, year)
As a display of knowledge, the author highlights how different hexadecimal notations represent different parts of the software. Along with knowledge of how hexadecimal instructions map to the instruction set of the specific chip of of the Commodore 64 (in this case, the SID 8580), the practical use of these instructions takes productive advantage of ambivalence and side-effects30.
Demosceners therefore tend to write concise, deliberate code which is hardly understandable by other programmers without explanation, and yet hand-optimized for the machine. In addition to software developers' attempts to make intelligible the purpose and means of the program text via their source code, this practice adds a perspective on the relationship between formal representation and understanding. Here, such representation does not support and enable understanding, but rather become a proof of the mastery and skill involved in crafting such a concise input for such an overwhelming output; it hints that one needs a degree of expert knowledge in order to appreciate these kinds of program texts.
Hackers are therefore programmers who write code within a variety of settings, from academia to hobbyists through professional software development, with an explicit focus on knowledge and skill. Yet, some patterns emerge. First, one can see the emphasis on the ad hoc , insofar as choosing the right tool for the right job is a requirement for hacker code to be valued positively. This requirement thus involves an awareness of which tool will be the most efficient at getting the task at hand done, with a minimum of effort and minimum of overhead, usually at the expense of sustaining or maintaining the software beyond any immediate needs, making it available or comprehensible neither across time nor across individuals, a flavour of locality and technical context-sensitivity . Second, this need for knowing and understanding one's tools hints at a material relationship to code, whether instructions land in actual physical memory registers, staying away from abstraction and remaining in concrete reality by using magic numbers , or sacrificing semantic clarity in order to "shave off" a character or two. Throughout, there is the recurring requirement of doing the most with the least, of written parsimony leading to executed expansiveness.
Hacking therefore involves knowledge: knowledge of the hardware, knowledge of the programming language used and knowledge of the tradeoffs acceptable all the while exhibiting an air of playfulness. They tend to get the job done and do it for the sake of doing it , at the expense of conceptual soundness. If hacking can be considered a way of doing which deals with the practical intricacies of programming, involving concrete knowledge of the hardware and the language, they stand at the polar opposite of another community of source code practitionners. Scientists who write source code (of which computer scientists are a subset) engage with progamming first and foremost at the conceptual level, with different locii of implementation: either as a theory , or as a model .
Scientists
Historically, programming emerged as a distinct practice from the computing sciences: not all programmers are computer scientists, and not all computer scientists are programmers. Nonetheless, scientists engage with programming and source code in distinct ways, and as such open up the landscape of the type of code which can be written, as well as the standards which support the evaluation of formally satisfying code. First, we will look at code being written outside of computer science research activities and see how the specific needs of usability, replicability and data structuring link back to standards of software development. Then, we will turn to the code written by computer scientists and examine how ideal of computation manifest themselves in concrete implementations.
Computation as a means
Scientific computing, defined as the use of computation in order to solve non-computer science tasks, started as early as the 1940s and 1950s in the United States, aiding in the design of the first nuclear weapons, aerodynamics and ballistics, among others (
Oberkampf, 2010)
Verification and Validation in Scientific Computing by William L. Oberkampf, Christopher J. Roy, 2010.
. Calculations necessary to the verification of theories in disciplines such as physics, chemistry or mathematics were handed over to the computing machines of the time for faster and more correct processing. Beyond the military applications of early computer technology, the advent of computing technology would prove to be of great assistance in physics and engineering, as shown by Harlow and Fromm's article on Computer Experiments in Fluid Dynamics 31, or the report on Man-Computer Symbiosis by J.C.R. Licklider (
Licklider, 1960)
Man-Computer Symbiosis by J. C. R. Licklider, 1960.
.
The remaining issue is to make computers more accessible to scientists who did not have direct exposure to this new technology, and therefore might be unfamiliar to the intricacies of their use. While universities can afford mainframe computers so that scientists do not have to wait for the personal computer revolution, another vector for simplification and accessibility is the development of adequate programming languages. The intent is to provide non-computer scientists with easy means to instruct the computer on how to perform computations relevant to their work, ultimately aiming to situate computation as the third pillar of science, along with theorization and experimentation (
Vardi, 2010)
Science has only two legs by Moshe Y. Vardi, 2010. [link]
.
Such an endeavour started with the BASIC32programming language. Developed in 1964 at Dartmouth College, it aimed at addressing this hurdle by designing " the world's first user-friendly programming language " (
Brooks, 2019)
Finally, a historical marker that talks about something important - Granite Geek by David Brooks, 2019. [link]
, and led the personal computer revolution by allowing non-technical individuals to write their own software. By the dawn of the 21nope! cmdcentury, scientific computing had increased in the scope of its applications, extending beyond engineering and experimental, so-called "hard" sciences, to social sciences and the humanities. It had also increased in the time spent developing and using software (
Prabhu, 2011Hannay, 2009)
A survey of the practice of computational science by Prakash Prabhu, Hanjun Kim, Taewook Oh, Thomas B. Jablin, Nick P. Johnson, Matthew Zoufaly, Arun Raman, Feng Liu, David Walker, Yun Zhang, Soumyadeep Ghosh, David I. August, Jialu Huang, Stephen Beard, 2011.
How do scientists develop and use scientific software? by Jo Erskine Hannay, Carolyn MacLeod, Janice Singer, Hans Petter Langtangen, Dietmar Pfahl, Greg Wilson, 2009.
, with the main programming languages used being MATLAB, C/C++ and Python. While C and C++'s use can be attributed to their historical standing, popularity amongst computer scientists, efficiency for systems programming and speed of execution, MATLAB and Python offer different perspectives. MATLAB, originally a matrix calculator from the 1970s, became popular with the academic community by providing features such as a reliable way to do floating-point arithmetic and a friendly graphical user interface (GUI). Along with its powerful array-manipulation features, this ability to visualize large series of data and plot it on a display largely contributed to MATLAB's popularity (
Moler, 2020)
A history of MATLAB by Cleve Moler, Jack Little, 2020. [link]
. The combination of
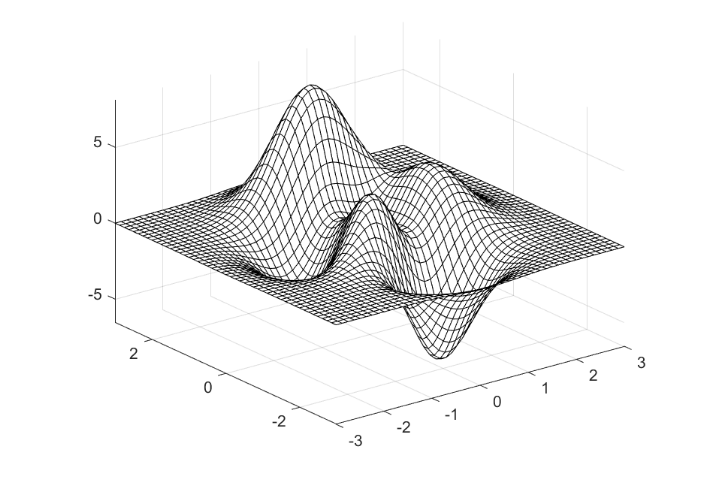
mesh_m
X = (-3:1/8:3)*ones(49,1);
Y = X';
Z = 3*(1-X).^2.*exp(-(X.^2) - (Y+1).^2) \
- 10*(X/5 - X.^3 - Y.^5).*exp(-X.^2-Y.^2) \
- 1/3*exp(-(X+1).^2 - Y.^2);
mesh(X,Y,Z)
- Matlab is a specialized language, focused on scientific and mathematical applications.
and
mesh-visualization
Visualization of a 3D-mesh in Matlab
shows how concise the plotting of a three-dimensional plane is in MATLAB. In the source code, it requires only one call to mesh
, and the output is a complete visual rendering, with reasonable and aesthetically pleasing visual default settings in the form of graded axes.
mesh_m
X = (-3:1/8:3)*ones(49,1);
Y = X';
Z = 3*(1-X).^2.*exp(-(X.^2) - (Y+1).^2) \
- 10*(X/5 - X.^3 - Y.^5).*exp(-X.^2-Y.^2) \
- 1/3*exp(-(X+1).^2 - Y.^2);
mesh(X,Y,Z)
- Matlab is a specialized language, focused on scientific and mathematical applications.
mesh-visualization
Visualization of a 3D-mesh in Matlab
Along with MATLAB, Python represents the advent of the so-called scripting languages: programming languages which offer readability and versatility, along with decoupling from the actual operating system that it is being executed on. System languages, such as C, are designed to interact directly with the computer hardware, and to constitute data structures from the ground up. On the other hand, scripting languages were designed and used in order to connect existing software systems or data sources together, most notably in the early days of shell scripting (such as Bash
, sed
or awk
, as seen in
select_lines_awk
awk'$3 > 6' data.txt
- This program text selects all the lines from an input file which is longer than 6 characters in the C programming language, in just one line of code. See the alternative implementation in 20 lines of code in .
) (
author, year)
. Starting with the late 1990s, and the appearance of languages such as Perl and Python, scripting languages became more widely used by non-programmers who already had data to work with and only needed the tools to exploit it. The development of additional scientific libraries such as SciKit , NumPy for mathematics and numerical work or NLTK for language processing and social sciences in Python complemented the language's ease of use by providing manipulation of complex scientific concepts (
author, year)
.
This steady rise of scientific computing has nonetheless highlighted the apparent lack of quality standards in academic software, and how the lack of value judgments on the software written might impact the reliability of the scientific output (
Hatton, 1994)
How accurate is scientific software? by L. Hatton, A. Roberts, 1994.
. Perhaps the most well-known instance of poor standards in programming was revealed by the leak of the source code of the Climate Research Unit from the University of East Anglia in 2009 (
Merali, 2010)
Computational science: ...Error by Zeeya Merali, 2010. [link]
. In the leak, inline comments of the authors show that particular variable values were chosen to make the simulation run, with scientific accuracy being only a secondary concern. Code reviews of external software developers point out to the code of the CRU leak as being a symptom of the general state of academic software33.
In response, the beginning of the 2000s has seen the desire to re-integrate the best practices of software engineering in order to correct scientific software's lack of accuracy, resulting in the formation of communities such as the Research Software Engineers (
Woolston, 2022)
Why science needs more research software engineers by Chris Woolston, 2022. [link]
. As we have seen above, software engineering had developed on their own since its establishment as an independent discipline and professional field. Such a split, described by Diane Kelly as a " chasm " (
Kelly, 2007)
A Software Chasm: Software Engineering and Scientific Computing by Diane F. Kelly, 2007.
then had to face the different standards to which commercial software and scientific software were held to. For instance, commercial software must be extensible and performant, two qualities that do not necessarily translate to an academic setting, in which software might be written within a specific, time-constrained, research project, or in which access to computing resources (i.e. supercomputers) might be less of a problem.
It seems that software's position in the scientific inquiry is no longer that of a helpful crutch, but rather of an inevitable step. Within Landau et. al's conception of the scientific process as the progression from problem to theory, followed by the establishment of a model, the devising of a method, and then on to implemementation and finally to assessment (
Landau, 2011)
A Survey of Computational Physics: Introductory Computational Science by Rubin H. Landau, José Páez, Cristian C. Bordeianu, 2011. [link]
, code written as academic software is involved in the latter two stages of method and implementation. As such, it has to abide by the processes and requirements of scientific research. First and foremost, reproducibility is a core requirement of scientific research in general and bugs in a scientific software system can lead to radically different ouptuts given slightly different input data, while concealing the origin of this difference, and compromising the integrity of the research and of the researcher. Good academic code, then, is one which defends actively against these, perhaps to the expense of performance and maintainability. This can be addressed by reliable error-handling, regular assertions of the state of the processed data and extensive unit testing (
Wilson, 2014)
Best Practices for Scientific Computing by Greg Wilson, D. A. Aruliah, C. Titus Brown, Neil P. Chue Hong, Matt Davis, Richard T. Guy, Steven H. D. Haddock, Kathryn D. Huff, Ian M. Mitchell, Mark D. Plumbley, Ben Waugh, Ethan P. White, Paul Wilson, 2014. [link]
.
Furthermore, a unique aspect of scientific software comes from the lack of clear upfront requirements. Such requirements, in software development, are usually provided ahead of the programming process, and should be as complete as possible. As the activity of scientists is defined by an incomplete understanding of the application domain, requirements tend to emerge as further knowledge is developed and acquired (
author, year)
. As a result, efforts have been made to familiarize scientists with software development best practices, so that they can implement quality software on their own. Along with field-specific textbooks34the most prominent initiative in the field is Software Carpentry , a collection of self-learning and teaching resources which aims at implementing software best practices across academia, for scientists and by scientists. Founded by Greg Wilson, the co-editor of Beautiful Code , the organization's title refers directly to equivalents in the field of software development.
We see a convergence of quality standards of broad academic software towards the quality standards of commercial software development. Meanwhile, computer science worked towards asserting and pursuing its own field of research, sometimes distinct from the discipline of programming. Unlike other scientific fields possesses its own specific standards of programming, taking software not as a means to an end, but as the end itself.
Computation as an end
Computer scientists are scientists whose work focuses on computation as an object, rather than as a tool. They study the phenomenon of computation, investigating its nature and effects through the development of theoretical frameworks around it. Originally derived from computability theory, as a branch of formal mathematical logic, computation emerged as an autonomous field from work in mechanical design and configuration, work on circuit and language design, work on mathematical foundations, information theory, systems theory and expert systems, computer science establishes its institutional grounding with the inauguration of the first dedicated academic department at Purdue University in 1962 (
Ifrah, 2001)
The universal history of computing : From the abacus to the quantum computer by Georges Ifrah, 2001. [link]
.
From this multifaceted heritage and academic interdisciplinarity, computer scientists identified key areas such as data structures, algorithms and language design as foundations of the discipline (
Wirth, 1976)
Algorithms + Data Structures by Niklaus Wirth, 1976.
. Thoughout the process of institutionalization, the tracing of the "roots" of computation remained a constant debate as to whether computer science exists within the realm of mathematics, of engineering or as a part of the natural sciences. The logico-mathematical model of computer science contends that one can do computer science without an electronic computer, while the engineering approach of computer science tends to put more practical matters, such as architecture, language design and systems programming (implicitly assuming the use of a digital computer) at the core of the discipline; both being a way to generate and process information as natural phenomenon (
Tedre, 2006)
The development of computer science: A sociocultural perspective by Matti Tedre, 2006. [link]
.
The broad difference we can see between these two conceptions of computer science is that of episteme and techne . On the theoretical and scientific side, computer science is concerned with the primacy of ideas, rather than of implementation. The quality of a given program is thus deduced from its formal (mathematical) properties, rather than its formal (aesthetic) properties. The first manifestations of such a theoretical focus can be found in the Information Processing Language in 1956 by Allen Newell, Cliff Shaw and Herbert Simon, which was originally designed and developed to prove Bertrand Russell's Principia Mathematica (
Ifrah, 2001)
The universal history of computing : From the abacus to the quantum computer by Georges Ifrah, 2001. [link]
. While the IPL, as one of the very first programming languages, influenced the development of multiple subsequent languages, in particular some later languages came to be known as logic programming languages. These are based on a formal logic syntax of facts, rules and clauses about a given domain and whose correctness can be easily proven. We can see in
prolog_sample
% induce(E,H) <- H is inductive explanation of E
induce(E,H):-induce(E,[],H).
induce(true,H,H):-!.
induce((A,B),H0,H):-!,
induce(A,H0,H1),
induce(B,H1,H).
induce(A,H0,H):-
/* not A=true, not A=(_,_) */
clause(A,B),
induce(B,H0,H).
induce(A,H0,H):-
element((A:-B),H0), % already assumed
induce(B,H0,H). % proceed with body of rule
induce(A,H0,[(A:-B)|H]):- % A:-B can be added to H
inducible((A:-B)),% if it's inducible, andnot element((A:-B),H0), % if it's not already there
induce(B,H0,H). % proceed with body of rule
- The Prolog programming language focuses first and foremost on logic predicates in order to perform computation, rather than more practical system calls.
an example of the Prolog logic programming language. Its syntax appears very repetitive, a result of the few keywords used ( induce
, element
and clause
), and drawing directly from the lexical field of logic and framing the problem domain. Due to its Turing-completeness, one can write in Prolog programs such as language processing, web applications, cryptography or database programming, but its use seems to remain limited outside of theoretical circles in 2021, according to the Stackoverflow Developer survey for popular language uses (
Overflow, 2021)
Stack Overflow Developer Survey 2021 by Stack Overflow, 2021. [link]
.
prolog_sample
% induce(E,H) <- H is inductive explanation of E
induce(E,H):-induce(E,[],H).
induce(true,H,H):-!.
induce((A,B),H0,H):-!,
induce(A,H0,H1),
induce(B,H1,H).
induce(A,H0,H):-
/* not A=true, not A=(_,_) */
clause(A,B),
induce(B,H0,H).
induce(A,H0,H):-
element((A:-B),H0), % already assumed
induce(B,H0,H). % proceed with body of rule
induce(A,H0,[(A:-B)|H]):- % A:-B can be added to H
inducible((A:-B)),% if it's inducible, andnot element((A:-B),H0), % if it's not already there
induce(B,H0,H). % proceed with body of rule
- The Prolog programming language focuses first and foremost on logic predicates in order to perform computation, rather than more practical system calls.
Lisp— LISt Processor — is another programming language which shares this feature of theoretical soundness faced with a limited range of actual use in production environments. It was developed in 1958, the year of the Dartmouth workshop on Artificial Intelligence, by its organizator, John McCarthy, and was designed to process lists. Inheriting from IPL, it retained the core idea that programs should separate the knowledge of the problem (input data) and ways to solve it (internal rules), assuming that the rules are independent to a specific problem.
The base structural elements of Lisp are not symbols, but lists (of symbols, of lists, of nothing), and they themselves act as symbols (e.g. the empty list). By manipulating those lists recursively—that it, processing something in terms of itself—Lisp highlights even further this tendency to separate computation from the problem domain, exhibiting autotelic tendencies. This is facilitated by its atomistic and relational structure: in order to solve what it has do, it evaluates each symbol and traverses a tree-structure in order to find a terminal symbol. Building on these features of complex structures with simple elements, Willam Byrd, computer scientst at the University of Utah, describes the Scheme interpreter written in Scheme35shown in (
- Scheme interpreter written in Scheme, revealing the power and self-reference of the language.
The beauty of such a program, for Byrd, is the ability of these fourteen lines of source to reveal powerful and complex ideas about the nature and process of computation. As an interpreter, this program can take any valid Scheme input and evaluate it correctly, recreating computation in terms of itself. It does so by showing and using ideas of recursion (with calls to eval-expr
), environment (with the evaluation of the body
) and lambda functions, as used throughout the program. Byrd equates the feelings he experiences in witnessing and pondering the program above to those suggested by Maxwell's equations, which constitute the foundation of classical electromagnetism (see
maxwell-equations
Maxwell's equations form a terse, unified basis for electromagnetism, optics and electric circuitry.
), a comparison that other computer scientists have made (
Kay, 2004)
A Conversation with Alan Kay - ACM Queue by Alan Kay, 2004. [link]
. In both cases, the quality ascribed to those inscriptions come from the simplicity and conciseness of their base elements—making it easy to understand what the symbols mean and how we can compute relevant outputs—all the while allowing for complex and deep consequences for, respectively, computer science and electromagnetism.
maxwell-equations
Maxwell's equations form a terse, unified basis for electromagnetism, optics and electric circuitry.
With this direct manipulation of symbolic units upon which logic operations can be performed, Lisp became the language of AI, an intelligence conceived first and foremost as abstractly logical. Lisp-based AI was thus working on what Seymour Papert has called "toy problems"—self-referential theorems, children's stories, or simple puzzles or games (
Nilsson, 2009)
EARLY EXPLORATIONS: 1950S AND 1960S by Nils J. Nilsson, 2009. [link]
. In these, the problem and the hardware are reduced from their complexity and multi-consequential relationships to a finite, discrete set of concepts and situations. Confronted to the real world—that is, to commercial exploitation—Lisp's model of symbol manipulation, which proved somewhat successful in those early academic scenarios, started to be applied to issues of natural language understanding and generation in broader applications. Despite disappointing reviews from government reports regarding the effectiveness of these AI techniques, commercial applications flourished, with companies such as Lisp Machines, Inc. and Symbolics offering Lisp-based development and support. Yet, in the 1980s, over-promising and under-delivering of Lisp-based AI applications, which often came from the combinatorial explosion deriving from the list- and tree-based representations, met a dead-end. In this case, a restricted problem domain can enable a particular value judgment, but also exclude others.
" By making concrete what was formerly abstract, the code for our Lisp interpreter gives us a new way of understanding how Lisp works ", notes Michael Nielsen in his analysis of Lisp, pointing at how, across from the episteme of computational truths stands the techne of implementation (
Nielsen, 2012)
Lisp as the Maxwell’s equations of software \textbar DDI by Michael Nielsen, 2012. [link]
. The alternative to such abstract, high-level language, is then to consider computer science as an engineering discipline, a shift between theoretical programming and practical programming is the publication of Edsger Dijkstra's Notes on Structured Programming . In it, he points out the limitation of considering programming exclusively as a concrete, bottom-up activity, and the need to formalize it in order to conform to the standards of mathematical logical soundness. Dijkstra argues for the superiority of formal methods through the need for a sound theoretical basis when writing software, at a time when the software industry is confronted with its first crisis.
Within the software engineering debates, the theory and practice distinction had a slightly different tone, with terms like “art” and “science” labeling two, implicitly opposed, perspectives on programming. Programming suffered from an earlier image of an inherently unmanageable, unsystematic, and artistic activity, many saw programming essentially as an art or craft (
Tedre, 2006)
The development of computer science: A sociocultural perspective by Matti Tedre, 2006. [link]
, rather than an exact science. Beyond theoretical soundness, computer science engineering concerns itself with quantified efficiency and sustainability, with measurements such as the O() notation for program execution complexity. It is not so much about whether it is possible to express an algorithm in a programming language, but whether it is possible to run it effectively, in the contingent environments of hardware, humans and problem domains36.
This approach, halfway between science and art, is perhaps best seen in Donald Knuth's magnum opus, The Art of Computer Programming . In it, Knuth summarizes the findings and achievements of the field of computer science in terms of algorithm design and implementation, in order to " to organize and summarize what is known about the fast subject of computer methods and to give it firm mathematical and historical foundations. " (
author, year)
. The art of computer programming, according to him, is therefore based on mathematics, but differs from it insofar as it does have to deal with concepts of effectiveness, implementation and contingency. In so doing, Knuth takes on a more empirical approach to programming than his contemporaries, inspecting source code and running software to assess their performance, an approach he first inaugurated for FORTRAN programs when reporting on their concrete effectiveness for the United States Department of Defense (
Defense Technical Information Center, 1970)
An Empirical Study of Fortran Programs by Defense Technical Information Center, 1970. [link]
.
Another influential textbook insisting that computation is not to be seen as an autotelic phenomenon is Structure and Interpretation of Computer Programs . In it, the authors insist that source code " must be written for people to read, and only incidentally for machines to execute " (
author, year)
. Readability is thus an explicit standard in the discipline of programming, along with a less visible focus on efficiency and verifiability. Finally, looking at the number of lines involved in each of the beautiful Julia algorithms listed, it seems that an inverse proportional relation between line numbers and complexity of the idea expressed is a part of the standards used to determine what makes such implementation of the algorithm satisfying. We can see such a value at play in the series Beautiful Julia Algorithms (
Moss, 2022)
BeautifulAlgorithms.jl by Robert Moss, 2022. [link]
. For instance,
bubble_sort_julia
function bubble_sort!(X)
for i in 1:length(X), j in 1:length(X)-i
if X[j] > X[j+1]
(X[j+1], X[j]) = (X[j], X[j+1])
end
end
end
- Bubble Sort implementation in Julia uses the language features to use only a single iteration loop.
(
Moss, 2021)
implements the classic Bubble Sort sorting algorithm in one loop rather than the usual two loops in C, resulting in an easier grasping of the concept at hand, rather than being distracted by the idiosyncracy of the implementation details. The simplicity of scientific algorithms is expressed even further in
nearest_neighbor_julia
function nearest_neighbor(x',phi, D, dist)
D[argmin([dist(phi(x),phi(x')) for (x,y) in D])][end]
end
- Nearest neighbor implementation in Julia .
(
author, year)
the one-line implementation of a procedure for finding a given element's nearest neighbor, a crucial component of classification systems.
bubble_sort_julia
function bubble_sort!(X)
for i in 1:length(X), j in 1:length(X)-i
if X[j] > X[j+1]
(X[j+1], X[j]) = (X[j], X[j+1])
end
end
end
- Bubble Sort implementation in Julia uses the language features to use only a single iteration loop.
(
Moss, 2021)
function nearest_neighbor(x',phi, D, dist)
D[argmin([dist(phi(x),phi(x')) for (x,y) in D])][end]
end
- Nearest neighbor implementation in Julia .
(
author, year)
According to Tedre, computer science itself was split in a struggle between correctness and productivity, between theory and implementation, and between formal provability and intuitive art (
Tedre, 2014)
The Science of Computing: Shaping a Discipline by Matti Tedre, 2014.
. In the early developments of the field, when machine time was expensive and every instruction cycle counted, different conflicting standards were used to assess the quality of the software written, as the machine's limitations remained unavoidable. Ultimately, the decoupling of electric engineering and programming enabled a certain process of autonomization when it came to aesthetic standards37
In closing, one should note that the Art in the title of Knuth's series does not, however, refer to art as a fine art, or a purely aesthetic object. In a 1974 talk at the ACM, Knuth goes back to its Latin roots, where we find ars , artis meaning "skill.", noting that the equivalent in Greek being τεχνη, the root of both "technology" and "technique.". This semantic proximity helps him reconcile computation as both a science and an art, the first due to its roots in mathematics and logic, and the second
because it applies accumulated knowledge to the world, because it requires skill and ingenuity, and especially because it produces objects of beauty. A programmer who subconsciously views himself as an artist will enjoy what he does and will do it better. Therefore we can be glad that people who lecture at computer conferences speak about the state of the Art. (
author, year)
When written within an academic and scientific context, source code tends to align with the aesthetic standards of software development, valuing reliability, reabability, sustainability, for instance through Greg Wilson's work on the development of software development principles through the Software Carpentry initiative. This alignment can also be seen in a conception of computer science as a kind of engineering, as an empirical practice which can and should still be formalized in order to become more efficient. There, one can turn to Donald Knuth's Art of Computer Programming to see the connections between the academia's standards and the industry's standards.
And yet, a conception of computation as engineering isn't the only conception of computer science. Within a consideration of computer science as a theoretical and abstract object of study, source code becomes a means of providing insights into more complex abstract concepts, seen in the Lisp interpreter, or one-line algorithms implementing foundational algorithms in computer science. The beauty of scientific source code is thus associated with the beauty of other sciences, such as mathematics and engineering. And yet, Knuth is also known as the advocate of literate programmig, a practice which engages first source code as a textual, rather than scientific, object. To address this nature, we complete our overview of code practitioners by turning to the software artists, who engage most directly with program texts through source code poetry.
Poets
Ever since Christopher Stratchey's love letters, programmers have been curious of the intertwining of language and computation. Electronic literature is a broad field encompassing natural language texts taking full advantage of the dynamic feature of computing to redefine the concept of text, authorship and readership. It encompasses a variety of approaches, including generative literature, interactive fiction, visual poetry, source code poetry and esoteric programming languages, as well as certain aspects of software art. Here, we focus here only on the elements of electronic literature which shift their focus from output to input, from executable binary with transformed natural language as a result, to static, latent source. Particularly, we pay attention to the role of function, correctness and meaning-making in these particular program texts.
Code poetry as executed literature
Electronic literature, a form based on the playful détournement of the computer's constraints, gets closer to our topic insofar as the poems generated represent a more direct application of the rule-based paradigm to the syntactical output of the program. Starting in 1953 with Christopher Stratchey's love letters, generated (and signed!) by MUC, the Manchester Univac Computer, computer poems are generated by algorithmic processes, and as such rely essentially on this particular feature of programming: laying out rules in order to synthesize syntactically and semantically sound natural language poems. Here, the rules themselves matter only in relation to the output, as seen by their ratio: a single rule for a seemingly-infinite amount of outputs, with these outputs very often being the only aspect of the piece shown to the public.
These works and their authors build on a longer tradition of rule-based composition, from Hebrew to the Oulipo and John Cage's indeterministic composition, amongst others (
author, year)
, a tradition in which creativity and beauty can emerge from within a strict framework of formal rules. Nonetheless, the source code to these works is rarely released in conjunction with their output, hinting again at their lesser importance in terms of their overall artistic values. If electronic literature is composed of two texts, a natural-language output and a computer-language source, only the former is actually considered to be poetry, often leaving the latter in its shadow (as well as, sometimes, its programmer, an individual sometimes different from the poet). The poem exists through the code, but isn't exclusively limited to the human-readable version of the code, as it only comes to life and can be fully appreciated, under the poet's terms, once interpreted or compiled. While much has been written on electronic literature, few of those commentaries focus on the soundness and the beauty of the source code as an essential component of the work, and only in recent times have we seen the emergence of close-readings of the source of some of these works for their own sake (
Montfort, 2014Marino, 2020author, year)
10 PRINT CHR$(205.5+RND(1)); : GOTO 10 by Nick Montfort, Patsy Baudoin, John Bell, Ian Bogost, Jeremy Douglass, 2014.
Critical Code Studies by Mark C. Marino, 2020.
. These constitute a body of work centered around the concept of generative aesthetics (
author, year)
, in which beauty comes from the unpredictable and somewhat complex interplay of rule-based systems, and whose manifestations encompass not only written works, but games, visual and musical works as well.
Source code poetry is thus a form of electronic literature, but also a form of software art. Software art is an umbrella term regrouping artistic practices which engage with the computer on a somewhat direct, material level, whether through hardware38or software39. This space for artistic experimentation flourished at the dawn of the 20th century, with initiatives such as the Transmediale festival's' introduction of a software art award between 2001 and 2004, or the Run\_me festival, from 2002 to 2004. In both of these, the focus is on projects which incorporate standalone programmes or script-based applications which are not merely functional tools, but also act as an effective artistic proposition, as decided by the artist, jury and public. These works often bring the normally hidden, basic materials from which digital works are made (e.g. code, circuits and data structures) into the foreground (
Yuill, 2004)
Code Art Brutalism: Low-level systems and simple programs by Simon Yuill, 2004. [link]
. From this perspective, code poetry is a form a software art where execution is required, but not sufficient to constitute a meaningful work.
The approach of code poets is therefore more specific than broad generative aesthetics: it is a matter of exploring the expressive affordances of source code, and the overlap of machine-meaning and human-meaning, acting as a vector for artistic communication. Such an overlap of meaning is indeed the specific feature of source code poetry. In a broad sense, code poetry conflates classical poetry (as strict syntactical and phonetical form, combined with poetic expressivity) with computer code, but it is primarily defined by its inversion of the reading and executing processes. Usually, a program text is loosely assumed to be somewhat pleasurable to read, but is expected to be executable. Code poems rather assume that the program text is somewhat executable, but demand that it is pleasurable to read. Following the threads laid out by electronic literature, code poetry starts from this essential feature of computers of working with strictly defined formal rules, but departs from it in terms of utility. Code poems are only functional insofar as they are accepted by the intepreter or compiler of the language in which they are written, but they are functional nonetheless. The are functional to the computer, in that they are composed in a legal syntax and can be successfully parsed; but they do not need their output to do anything of immediate and measurable use . Such formal compliance is only a pre-requisite, a creative constraint, for their human writers, and their formal approach to minimizing matter and maximizing concept is, as we will see, not limited to a literary poetry, but can also be encountered in architecture or science.
Within this reliance on creative constraints provided by a computing environment, the emphasis here is on the act of reading, rather than on the act of deciphering, as we have seen with obfuscated code (and in functional code in general). Source code poems are often easy to read, and have an expressive power which operates beyond the common use of programming. They also make the reader reconsider the relationship to the machine, and the relationship to function. By using a machine language in the way the machine expects to receive it, it is no longer software referring to itself, exploring its own poetics and its specific meaning-making abilities. By forcing itself to be functional—that is, to produce meaningful output as the result of execution, it becomes software investigating itself, and through that, investigating the system within which it exists and acts, and the assumptions we ascribe to it. Code poems thus shed a new light on how and why source code is written, not as a functional artefact, but as a poetic one, focusing on fabrication rather than production, and expressing a subject rather than an intent (
author, year)
.
In their different manifestations, code poems make the boundary between computer meaning and human meaning thinner and thinner, a feature often afforded by the existence and use of higher-level programming languages. Starting with the development of FLOWMATIC in 1955 by Grace Hopper, it was shown that an English-like syntactical system could be used to communicate concepts for the computer to process. From there, programming languages could be described along a gradient, with binary at the lowest end, and natural language (in an overwheling majority, English) at the highest end. This implies that they could be written and read similarly to English, including word order, pronouncation and interpretation, similar to the error-tolerance of human laguages, which doesn't cause the whole communication process to fail whenever a specific word, or a word order isn't understood.
Layered machine texts
Yet, code poems from the 20th century aren't the first time where a part of the source code is written exclusively to elicit a human reaction, without any machinic side-effects. One of the earliest of those instances is perhaps the Apollo 11 Guidance Computer (AGC) code, written in 1969 in Assembly (
Garry, 1969)
LUNAR_LANDING_GUIDANCE_EQUATIONS.agc by Chris Garry, Margaret Hamilton, 1969. [link]
. Cultural references and jokes are peppered throughout the text as comments, asserting computer code as a means of expression beyond exclusively technical tasks40, and independent from a single writer's preferences, since they passed multiple checks and review processes to end up in the final, submitted and executed document, such as reproduced in
numero_mysterioso_asm
663 STODL CG
664 TTF/8665 DMP* VXSC
666 GAINBRAK,1 # NUMERO MYSTERIOSO
667 ANGTERM
668 VAD
669 LAND
670 VSU RTB
- AGC source code for the Lunar Landing Guidance Equation, 1969
.
numero_mysterioso_asm
663 STODL CG
664 TTF/8665 DMP* VXSC
666 GAINBRAK,1 # NUMERO MYSTERIOSO
667 ANGTERM
668 VAD
669 LAND
670 VSU RTB
- AGC source code for the Lunar Landing Guidance Equation, 1969
Code comments allow a programmer to write in their mother tongue, rather than in the computer's, enabling more syntactic and semantic flexibility, and thus reveal a burgeoning desire for programmers to express themselves within their medium of choice, in the midst of an impersonal interaction with the machine system.
Rather than limiting their lexical field to comments, some writers decided to engage directly with machine keywords in order to compose poems. One of the first instances of this human poetry composed with machine syntax are the Poèmes Algol by Noël Arnaud (
Arnaud, 1968)
Poèmes ALGOL by Noël Arnaud, 1968.
. As a member of the Oulipo movement, he sets himself the constraints of only using those reserved keywords of the ALGOL 68 programming language to extract meaning beyond their original purpose. Reading those, one is first struck by their playfulness in pronounciation, and subsequently by the unexpected linguistic associations that they suggest.
More recently, this has been illustrated in the work of MOONBIT (
Mosteirin, 2019)
Moonbit by Rena J. Mosteirin, James E. Dobson, 2019. [link]
, a series of code poems computationally extracted from the AGC's source code, with those two program texts standing almost 50 years apart. In their work, the authors want to highlight that software is not only functional, but also social, political and aesthetic; importantly, the relation between aesthetics and function is not seen as mutually exclusive, but rather as supplementary41. As programmers could already express themselves in a language as rigid as Assembly, subsequent programming languages would further expand poetic possibilities.
Code poetry benefited greatly from the advent of scripting languages, such as Python, Ruby or Perl (seeScientists
above). As we've seen, scripting languages are readable and versatile; readable because their syntax tends to borrow from natural languages rather than invented idioms, at the expense of functionality42, and versatile because they often handle some of the more complex and subtle data and platform idiosyncracies43.
The community of programmers writing in Perl44has been one of the most vibrant and productive communities when it comes to code poetry. This particular use of Perl started in 1990, when the language creator Larry Wall shared some of the poems written in the language, and it gained further exposition through the work of Shannon Hopkins (
author, year)
. The first Perl poem is considered to have been written by Wall in 1990, reproduced in
japh_perl
print STDOUT q
Just another Perl hacker,
unless $spring
- Just Another Perl Hacker, part of a typology of program texts showing linguistic ingenuity rather than computational efficiency.
.
japh_perl
print STDOUT q
Just another Perl hacker,
unless $spring
- Just Another Perl Hacker, part of a typology of program texts showing linguistic ingenuity rather than computational efficiency.
Hopkins analyzes the ability of the poem to enable dual understandings of the source—human and machine. Yet, departing from the previous conceptions of source that we have looked at, code poetry does not aim at expressing the same thing to the machine and to the human. The value of a good poem comes from its ability to evoke different concepts for both readers of the source code. As Hopkins puts it:
In this poem, the q operator causes the next character (in this case a newline) to be taken as a single quote, with the next occurrence of that delimiter taken as the closing quote. Thus, the single-quoted line 'Just another Perl hacker' is printed to STDOUT. In Perl, the "unless $spring" line is mostly filler, since $spring is undefined. In poetical terms, however, "$spring" is very important: haiku poetry is supposed to specify (directly or indirectly) the season of the year. As for the q operator, that reads in English as the word "queue", which makes perfect sense in the context of the poem. (
author, year)
The poem Black Perl , submitted anonymously in 1990, is another example of the richness of the productions of this community. It is presented in
black_perl
#!/usr/bin perlno warnings;
BEFOREHAND: close door, each window & exit; waituntil time.
open spellbook, study, read (scan, $elect, tell us);
write it, print the hexwhileeach watches,
reverse its, length, write, again;
kill spiders, pop them, chop, split, kill them.
unlink arms, shift, wait & listen (listening, wait),
sort the flock (then, warn"the goats" & kill"the sheep");
kill them, dump qualms, shift moralities,
values aside, each one;
die sheep? die to : reverse { the =>system
( you accept (reject, respect) ) };
next step,
kill`the next sacrifice`, each sacrifice,
wait, redo ritual until"all the spirits are pleased";
do { it =>"as they say" }.
do { it => (*everyone***must***participate***in***forbidden**s*e*x*)
+ }.
returnlast victim; package body;
exitcrypt (time, times & "half a time") & close it,
select (quickly) & warn your (next victim);
AFTERWARDS: tell nobody.
wait, waituntiltime;
waituntilnext year, next decade;
sleep, sleep, die yourself,
die @last
- Black Perl is one of the first Perl poems, shared anonymously online. It makes creative use of Perl's flexible and high-level syntax.
in its updated form by kck, making it compatible for perl 5.20 in 2017. The effort of Perl community members of updating Black Perl to more recent versions of the language is a testament to the fact that one of the intrinsic qualities of the poem is its ability to be correctly processed by the language interpreter.
black_perl
#!/usr/bin perlno warnings;
BEFOREHAND: close door, each window & exit; waituntil time.
open spellbook, study, read (scan, $elect, tell us);
write it, print the hexwhileeach watches,
reverse its, length, write, again;
kill spiders, pop them, chop, split, kill them.
unlink arms, shift, wait & listen (listening, wait),
sort the flock (then, warn"the goats" & kill"the sheep");
kill them, dump qualms, shift moralities,
values aside, each one;
die sheep? die to : reverse { the =>system
( you accept (reject, respect) ) };
next step,
kill`the next sacrifice`, each sacrifice,
wait, redo ritual until"all the spirits are pleased";
do { it =>"as they say" }.
do { it => (*everyone***must***participate***in***forbidden**s*e*x*)
+ }.
returnlast victim; package body;
exitcrypt (time, times & "half a time") & close it,
select (quickly) & warn your (next victim);
AFTERWARDS: tell nobody.
wait, waituntiltime;
waituntilnext year, next decade;
sleep, sleep, die yourself,
die @last
- Black Perl is one of the first Perl poems, shared anonymously online. It makes creative use of Perl's flexible and high-level syntax.
The most obvious feature of this code poem is that it can be read by anyone, including by readers with no previous programming experience: each word is valid both as English and as Perl. A second feature is the abundant use of verbs. Perl belongs to a family of programming languages grouped under the imperative paradigm, which matches a grammatical mood of natural languages, the imperative mood . Such mood emphasizes actions to be take rather than, for instance, descriptions of situations, and thus sets a clear tone for the poem. The fact that Perl is based on stating procedures to be executed and states to be changed creates this feeling of relentless urgency when reading through the poem, a constant need to be taking actions, for things to be changed. Here, the native constraints of the programming language interacts directly with the poetic suggestion of the work in a first way: the nature of Perl is that of giving orders, resulting in a poem which addresses someone to execute something . Still, Perl's flexibility leaves us wondering as to who and what are concerned by these orders. Is the poem directing its words to itself? To the reader? Is Perl just ever talking exclusively to the computer? This ambiguity of the adressee adds to the ominousness of each verse.
The object of each of these predicates presents a different kind of ambiguity: earlier versions of Perl function in such a way that they ignore unknown tokens4546. Each of the non-reserved keywords in the poem are therefore, to the Perl interpreter, potentially inexistant, allowing for a large latitude of creative freedom from the writer's part. Such a feature allows for a tension between the strict, untoucheable meaning of Perl's reserved keywords, and the almost infinite combination of variable and procedure names and regular expressions. This tension nonetheless happens within a certain rhythm, resulting from the programming syntax: kill them, dump qualms, shift moralities
, here alternating the computer's lexicon and the poet's, both distinct and nonetheless intertwined to create a Gestalt , a whole which is more than the sum of its parts.
A clever use of Perl's handling of undefined variables and execution order allows the writer to use keywords for their human semantics, while subverting their actual computer function. For instance, the die
function should raise an exception, but wrapped within the exit ()
and close
keywords, the command is not interpred and therefore never reaches the execution point, bypassing the abrupt interruption. The subversion here isn't purely semiotic, in the sense of what each individual word means, but rather in how the control flow of the program operates—technical skill is in this case required for artistic skill to be displayed.
Finally, the use of the BEFOREHAND:
and AFTERWARDS:
words mimick computing concepts which do not actually exist in Perl's implementation: the pre-processor and post-processor directives. Present in languages such a C, these specify code which is to be executed respectively before and after the main routine. In this poem, though, these patterns are co-opted to reminisce the reader of the prologue and epilogue sometimes present in literary texts. Again, these seem to be both valid in computer and human terms, and yet seem to come from different realms.
This instance of Perl poetry highlights a couple of concepts that are particularly present in code poetry. While it has technical knowledge of the language in common with obfuscation, it departs from obfuscated works, which operate through syntax compression, by harnessing the expressive power of semiotic ambiguity, giving new meaning to reserved keywords. Such an ambiguity is furthermore bi-directional: the computing keywords become imbued with natural language significance, bringing the lexicon of the machine into the realm of the poetic, while the human-defined variable and procedure names, and of the regular expressions, are chosen as to appear in line with the rhythm and structure of the language. Such a work highlights the co-existence of human and machine meaning inherent to any program text47.
Following in the footsteps of the perlmonks , additional communities around code poetry have formed, whether in university settings, such as Stanford's Code Poetry Slam, which ran between 2014 and 2016 (
Kagen, 2016)
Code Poetry Slam by Melissa Kagen, Kurt James Werner, 2016. [link]
, or as independent intiatives, like the Source Code Poetry event, which runs annual contests (
Unknown, 2017)
. The simple constraint and low barrier to entry also results in collective writings where programmers engage in playful writing, such as in the #SongsOfCode
trend on a micro-blogging website where the challenge is to represent a popular pop song in source code. In
- \#SongsInCode is an example of functional source code poetry written to represent the tradionally non-functional domain of pop songs.
, we can see a simple example of translation from the problem of popular pop songs into machine language. The tension between the familiarity of the song and the estrangeness of the Java syntax is a kind of puzzle that is also reminiscent of hackers, further establishing cognitive engagement as a factor in the judgment of positivel-valued source code poetry.
that the transition of programming from an annex practice to a full-fledged discipline and profession resulted in source code being recognized as a text in its own, to which engineering and artistic attention should be paid. No longer a transitional state from formula to binary, it becomes a semantic material, whose layout, organization and syntax are important to the eyes of its writers and readers. Pushing further into the direction of the visual layout of the code, such an endeavour becomes pursued for its own sake, existing parallel to the need for a program to be functional, and echoing the practice of Guillaume Apollinaire's calligrammes .
There, the physical layout of the program text comes to the forefront, along with its executed representation. Written by Kerr and Holden in 2014, water.c
is a poem written in C which illustrate both of these components. In
- This poem has a very deliberate layout and syntax, reminiscing of .
(
Holden, 2016)
./code –poetry by Mr Daniel Holden, Mr Chris Kerr, 2016.
, we can see that the way the whitespace is controlled in the source code evokes a visual representation of water as three columns composed of ;, { and { characters, computer-understood punctuation which nonetheless holds only a tiny semantic load as block and statement delimiters.
- This poem has a very deliberate layout and syntax, reminiscing of .
(
Holden, 2016)
./code –poetry by Mr Daniel Holden, Mr Chris Kerr, 2016.
Once compiled and executed, water.c
gains an additional quality: its output represents moving droplets running across the screen, with a particular frame shown in
water_out
; ; ; ; ; ;;;
- The output of consists in ASCII representation of water droplets, bearing a family resemblance to BASIC one liners, and suggesting a complementary representation of water.
. We see that code poetry, like other forms of writing program texts, differ from other means of expression in their dual representatiom, as source and software, static and dynamic.
water_out
; ; ; ; ; ;;;
- The output of consists in ASCII representation of water droplets, bearing a family resemblance to BASIC one liners, and suggesting a complementary representation of water.
Code poetry values code which, while being functional, expresses more than what it does, by allowing for Sprachspiele , languages games where pronounciation, syntax and semantics are playfully composed into a fluid linguistic construct in order to match a human poetic form, such as the haiku, or to constitute a specific puzzle. A subtle interplay of human meaning and machine meaning, layout and execution allows for a complex poetic emergence.
-
From engineers to poets, this section has shown how the set of individuals who write and read code is heterogeneous, varying in practices, problems and approaches. While none of these communities of practice are mutually exclusive—a software developer by day can hack on the weekend and participate in code poetry events—, they do help us grasp how source code's manifestations in program texts and its evaluation by programmers can be multifaceted. For instance, software engineers prefer code which is modular, modifiable, sustainable and understandable by the largest audience of possible contributors, while hackers would favor conciseness over expressivity, and tolerate playful idiosyncracy for the purpose of immediate, functional efficiency, with a practical engagement with the tools of their trade. On the other hand, scientific programming favors ease of use and reproducibility, along with a certain quest to represent the elegant concepts of computer science, while code poets explore the semantic tension between a human interpretation and the machine interpretation of a given source code, via syntactic games, graphical layouts and interplay between the static and executed versions of software.
Still, there are strands of similarity within this apparent diversity. The code snippets in this section show that there is a tendency to prefer a specific group of qualities—readability, conciseness, clarity, expressivity and functionality—even though different types of practices would put a different emphasis on each of those aspects. The question we turn to next, then, is to what extent do these different practices of code writing and reading share common judgments regarding their formal properties? To start this investigation, we first analyze programmers' discourses inIdeals of beauty
in order to identify concrete categories of formal properties which might enable a source code to be positively valued for its appearance, before we examine the aesthetic domains code practitioners refer to when discussing beautiful code inAesthetic domains